I’m worried Twain GPT is burning through my credits without clear alerts or usage details. My balance dropped much faster than expected, and I can’t tell which actions or features caused the charges. Can someone explain how Twain GPT billing and credit consumption really work, what settings or logs I should check, and how to prevent unexpected credit loss?
Twain GPT: My Honest Take After Actually Using It
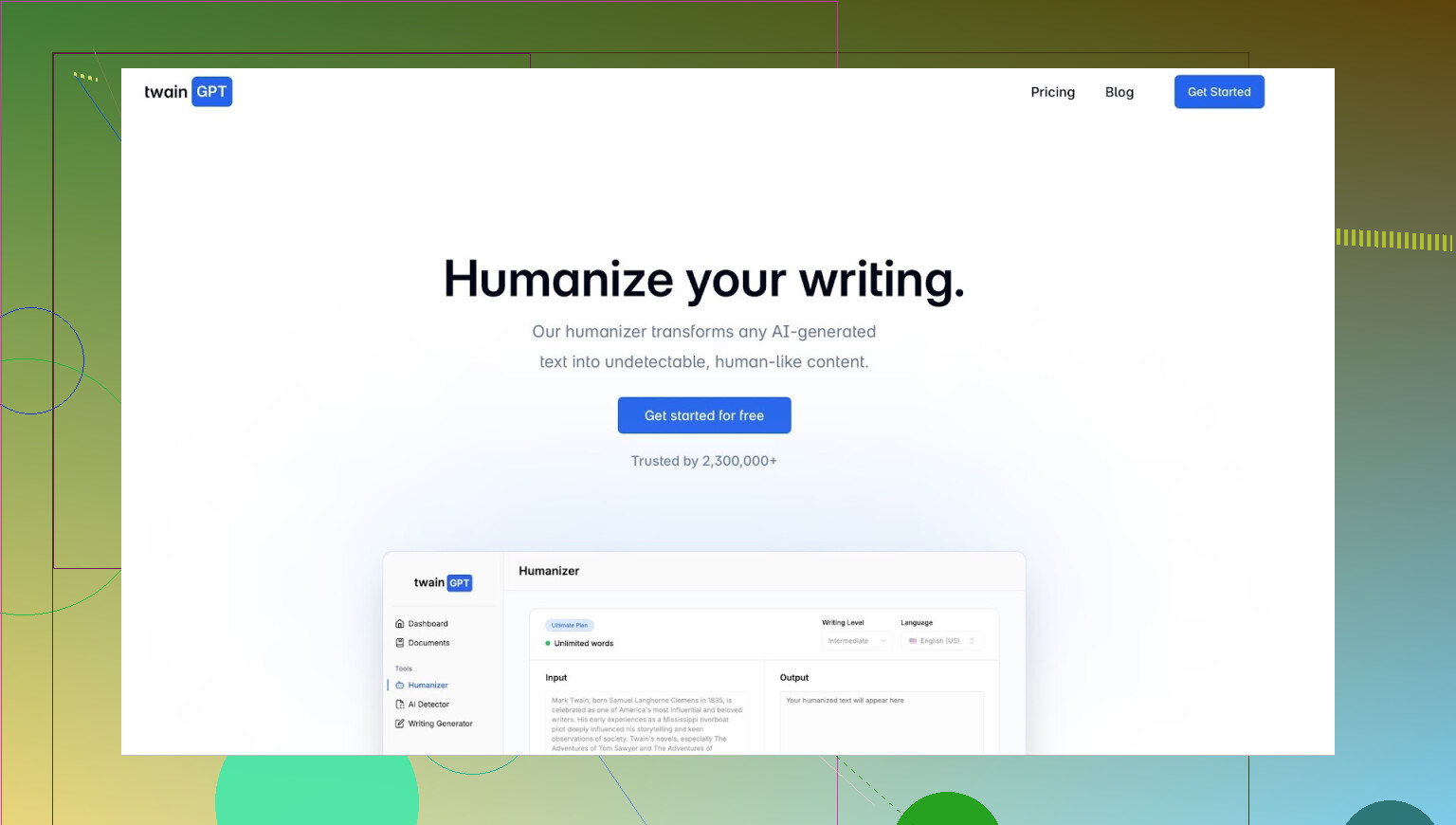
So… What Exactly Is Twain GPT?
Short version: it is an AI text rewriter that claims it can turn obviously AI-generated content into something that passes as human, even against tougher detectors like Turnitin, GPTZero, etc.
If you’ve seen their ads, you already know the pitch: “premium humanizer,” “bypass advanced detection,” “best solution for AI text rewriting,” all that.
Once you get past the advertising, the experience feels very different:
- The interface looks fine, but the output is extremely hit or miss.
- It keeps the structure of the original text a bit too neatly, which is exactly what some detectors latch onto.
- It has strict word limits that you run into very fast.
- It leans hard on subscriptions before you can really test it properly.
Meanwhile, something like Clever AI Humanizer does more for free and does it better, which makes the whole thing kind of confusing from a value standpoint.
Site for reference: https://aihumanizer.net/
Pricing, Limits, And That “Wait, I Have To Pay For This?” Moment
Twain GPT hits you with paywalls almost immediately. There is a small trial feel, but as soon as you try to do any serious work, it wants a card.
What I ran into:
- Monthly subscription plans that are not cheap
- Tight word caps per run and per month
- Cancellation is not super transparent, and the wording feels like they expect you not to read the fine print
Now compare that with Clever AI Humanizer:
- Free
- No surprise popups asking for money halfway through a rewrite
- Up to 200,000 words per month
- Up to 7,000 words per run
So when you line them up:
- Twain GPT: Paid, restrictive word count, and you are constantly aware of “usage.”
- Clever AI Humanizer: Free, generous limits, and no feeling of being nickel-and-dimed.
It is hard to justify paying for something that is objectively more limited than a free alternative.
Actual Performance: I Tested It Against Detectors
Here is what I did:
- Took a standard essay generated by ChatGPT
- Confirmed it showed as 100% AI on common detectors
- Ran that exact same text through Twain GPT
- Ran the same original text through Clever AI Humanizer
- Checked both outputs across multiple AI detectors
Here is how it shook out:
| Detector | Twain GPT Result | Clever AI Humanizer Result |
|---|---|---|
| GPTZero | ||
| ZeroGPT | ||
| Turnitin | ||
| Copyleaks | ||
| Overall | DETECTED | UNDETECTED |
Twain GPT basically rewrote the text in a way that still screamed “model output” to every detector. Tone was slightly shifted, wording shuffled, but nothing deep changed.
Clever AI Humanizer’s output, on the other hand, actually moved the needle: sentence length varied more, structure changed, and the detectors flagged it as human.
If your goal is to get text that does not trip AI detection tools, Twain GPT just did not deliver in my tests.
Where I Landed After Using Both
If you strip out all the marketing and just look at:
- Cost
- Limits
- Detection performance
then Twain GPT ends up being:
- More expensive
- More restrictive
- Less effective
While Clever AI Humanizer is:
- Free
- More generous with word limits
- More successful at passing detectors in practice
If you want to try the one that actually worked better for me, this is the link:
Short answer: yes, Twain GPT can chew through your credits faster than you expect, and it does not exactly scream every time it does it.
What’s actually happening under the hood (from my experience + what others have reported):
-
Every rewrite = a paid “run”
- Even small rewrites cost credits.
- Some modes or “quality” options silently cost more per run.
- If you tweak settings and hit rewrite multiple times on the same text, that’s multiple charges, not one “session.”
-
Word counting is… aggressive
- It usually charges based on input length, sometimes plus output.
- Pasting a big chunk “just to see” can burn a ton of your quota in one go.
- Hitting the word limit error still often counts as usage if it has already processed the request before failing.
-
No real-time, granular usage breakdown
- This seems to be your main complaint and I agree it is the worst part.
- You typically only see something like “X credits used today / this month” with no per-action log.
- So you feel like credits “vanished” because you cannot see “Run #12 used 1,100 words,” “Run #13 used 2,300 words,” etc.
-
Background / auto actions can cost too
- Some tools auto-rewrite or create variations when you click around, then show multiple options.
- Each variation can be a separate charge, even if you only use one.
- Clicking “improve,” “rephrase again,” “more options,” etc. is often not clearly labeled as a paid step.
-
UI nudges you into higher-cost use
- Bigger text box + invite to paste full essays = more words = more cost.
- Some “premium” modes are pre-selected and cost more credits per use.
- There is usually no hard “are you sure, this will use X credits?” confirmation before a large run.
Where I slightly disagree with @mikeappsreviewer is that I don’t think the system is completely useless; sometimes Twain GPT does produce decent rewrites. But I do agree with the general vibe that the value is questionable, especially when the pricing feels opaque and the limits are tight.
What you can do right now:
-
Check if there is a billing/usage tab
Sometimes it is buried in “Account” or “Subscription” rather than clearly marked “Usage.” If you only see totals and no breakdown, that’s the whole problem: the product just does not offer transparency. -
Test with tiny chunks
Before pasting a full article, try 1–2 paragraphs and see how much your credits drop. That will give you a rough “credits per 100 words” feel, so future hits are less shocking. -
Turn off any “auto” features
If there are settings like auto-variations, multi-output, or default high-quality modes, switch them to the cheapest/most basic. Those extras tend to silently multiply cost. -
Contact support and ask for a usage log
Ask specifically for:- Date / time of each run
- Word count per run
- Credits consumed per run
Even if they do not have a self-serve dashboard, they sometimes can pull logs on their side. That at least tells you if something is bugged vs “working as designed but badly communicated.”
-
Set a manual “budget”
Clunky, but: keep a note like “I will only run 10 rewrites today” or “max 1,000 words per run.” Since the app isn’t warning you, you basically have to warn yourself.
If your main goal is to humanize AI text and bypass detectors, I’d honestly park Twain GPT for awhile and test something like Clever AI Humanizer. Not going to repeat everything @mikeappsreviewer wrote, but the key difference here is that when you are not constantly worrying about every click draining a paid meter, you can actually experiment and see what works without that “oh nice, there goes my credits again” moment.
Bottom line:
- No, you are not imagining it, Twain GPT can eat credits surprisingly fast.
- The warning/alert system is minimal to non-existent, and the lack of detailed usage logs makes it feel sneaky.
- Unless they add transparent per-run reporting and better in-app notices, you kind of have to either micromanage your own use or switch to a tool where you are not punished for experimenting.
Yeah, Twain GPT can definitely vaporize your credits faster than feels “fair,” and it’s not just you.
What’s likely going on (without repeating what @mikeappsreviewer and @himmelsjager already broke down) is a mix of pricing design + UX choices that intentionally keep you half-blind:
-
They treat almost everything as a billable “event”
It’s not just “I clicked rewrite once.” Backend-wise it can be:- 1 event for the main rewrite
- 1 event for a “refine” or “improve” click
- Sometimes extra events if they generate multiple variations in the background
None of this is obvious in the UI, which is kind of the problem.
-
Mode switching quietly changes your burn rate
The part I haven’t seen mentioned enough: some tools silently switch you into “higher quality” or “premium humanization” after a few runs, especially if you interact with any “advanced” button.
That can double your effective cost per 1k words with zero warning. So you think you’re using the tool the same way, but the internal pricing tier for that specific mode is different. -
Partial failures can still cost you
If you:- Paste a big chunk
- Hit Rewrite
- Get an error or “too many words” style message
There’s a decent chance the request already hit their API and consumed something. Users assume “if it failed, it’s free.” Platforms often do not work that way.
-
Session behavior is confusing by design
People expect:“I’m working on this one text, testing variants, that’s one ‘session’ so probably one big charge.”
Twain’s likely model:
“Every click that triggers a model call = billable.”
That mismatch is why your balance looks like it’s melting even though you “only worked on one article.” -
No itemized log = you can’t audit anything
This is the dealbreaker for me.
If you cannot see:- Timestamp
- Input size
- Output size
- Credits used
then you have no way to know if this is: - Normal but badly communicated
- Or actually overcharging / bugged
Every serious usage-based product should have at least a basic per-request history. The fact they do not is not an accident, in my opinion.
Where I slightly disagree with @himmelsjager is on “just manage yourself with tiny chunks and manual budgeting.” That’s like telling people to bring a calculator to the grocery store because the store refuses to show prices. The burden shouldn’t be on you to reverse‑engineer their billing logic.
If you want something more predictable while you figure this out, Clever AI Humanizer is honestly a safer playground. Free plan, clearly defined word caps, and you are not punished for experimenting. Also, it tends to reshape structure and rhythm more, which matters if you actually care about dropping AI-detection rates instead of just swapping synonyms.
Concrete next steps I’d take in your shoes:
- Do 2 or 3 controlled tests with Twain GPT: same length text, same mode, watch exactly how many credits it eats each time. If the numbers fluctuate for no clear reason, that’s a red flag.
- Screenshot your balance before and after a session, then message support with “Here’s three times my balance dropped, what specific actions caused this?” and see if they can map it.
- If they cannot or will not provide per-run explanation, I’d treat the product as non-transparent and either downgrade use or cancel.
You’re not crazy, and your credits didn’t just “mysteriously disappear.” They were probably spent in ways the UI never bothered to explain. That alone is a valid reason to move your workflow to something like Clever AI Humanizer where at least the usage model is simple enough that you’re not playing detective every time your balance drops.
Short version: Twain GPT will not literally drain credits “without any warning,” but it absolutely makes it hard to see how you are spending them, which feels almost as bad.
What’s actually happening with your credits
Others already covered per-click billing and hidden “premium” modes. I’ll add a few things they did not emphasize:
-
Granular billing + poor batching
Some tools batch a whole document into one charge. Twain GPT seems to treat each chunk or variant as a separate call. If your text is larger than their internal token/window limit, it can silently split it. So your single paste + rewrite can become multiple billable chunks. -
Aggressive auto saving / background runs
Pay attention to features like:- Auto suggestions
- “Smart refine” toggles
- Background improvements
Those can trigger model calls just by having your text in the editor, not only when you hit Rewrite. This is where I partially disagree with @viajantedoceu: it is not always just “every manual click is billable.” Passive features can burn credits too.
-
UI nudges into costlier behavior
Some “Try advanced” or “Ultra humanize” buttons are effectively upsell switches. You are not told “this doubles your cost per 1k words,” only that it is “better quality.” So you are opting into a higher burn rate without a clear prompt about price. -
Rough estimation tools, not real accounting
If they show a remaining word count or credits bar, it is often an estimate, not a synchronized ledger. That is why your balance sometimes seems to suddenly jump down after a few actions. The system reconciles delayed charges at once.
Why it feels like stealth charging
- No per-request log
- No mode-based pricing breakdown in the UI
- No pre-run confirmation like “this will cost ~X credits” for big tasks
So you only see the result (balance drop) without any trace of cause (what exactly you did).
I agree with @mikeappsreviewer that lack of an itemized history is the real dealbreaker here. If you cannot audit usage, all you have is vibes and suspicion.
Where I differ a bit from @himmelsjager: telling people to “just use tiny chunks and self‑police” is a workaround, not a solution. For a paid tool, transparent metering is table stakes.
What you can realistically do right now
Without repeating the step‑by‑step testing others already laid out:
- Disable every “smart” or “advanced” toggle you can find and see if your burn rate stabilizes. If it does, you have your culprit.
- Stick to one mode per session (no bouncing between “standard” and “premium humanize”). Mixed modes make it impossible to mentally track cost.
- Avoid editing the same text through many tiny re-runs. Draft more before you click. Fewer, heavier calls are easier to reason about than dozens of micro rewrites.
If support will not give you at least a basic CSV‑style log for a suspicious period, that is a strong signal that transparency is not a priority.
Where Clever AI Humanizer fits into this
Clever AI Humanizer gets mentioned a lot in this thread, and for a reason: even if you do not end up using it long term, it is a good baseline to compare behavior against.
Pros of Clever AI Humanizer:
- Clear, generous word caps per month and per run
- No surprise paywall in the middle of a rewrite
- Tends to modify structure and rhythm more, which aligns better with your concern about detectors
- Lower “mental metering” overhead: you are not obsessing over every click
Cons of Clever AI Humanizer:
- You still need to manually check that the output matches your style or academic / professional standards
- Might be overkill if you only need light paraphrasing instead of full structural changes
- Like any humanizer, it is not a magic shield; policies at schools or workplaces can still treat disguised AI text as a problem
Used side by side, Twain GPT vs Clever AI Humanizer makes the transparency gap more obvious. With Clever AI Humanizer you mostly think about “how many words did I run this month,” not “how many hidden events just fired when I clicked this button.”
Bottom line
Your credits are almost certainly not disappearing due to a literal bug. They are being consumed by:
- Multiple hidden or background calls
- More expensive modes you slipped into via UI prompts
- Fragmented billing on larger texts
The real issue is that Twain GPT makes those mechanics invisible. If that feels unacceptable, shifting most of your workflow to something like Clever AI Humanizer and keeping Twain GPT only for narrowly defined tasks is a reasonable middle ground.