Ich habe mich bisher auf die Bewertungen von Walter Writes AI verlassen, um zu entscheiden, welche Tools ich verwenden soll, aber ich fange an, Unstimmigkeiten und mögliche Fehler in dem Feedback zu bemerken, das es gibt. Einige Rezensionen wirken detailliert und vertrauenswürdig, während andere gehetzt oder sogar irreführend erscheinen. Hat noch jemand Probleme mit der Genauigkeit oder Zuverlässigkeit der Bewertungen von Walter Writes AI festgestellt, und wie überprüft ihr, ob seine Einschätzungen tatsächlich korrekt sind, bevor ihr ihnen vertraut?
Walter Writes AI Review von jemandem, der viel zu lange damit getestet hat
Walter Writes AI klang auf dem Papier interessant, also habe ich ein paar Tests gefahren und die Zahlen mitgeschrieben. Kurz gesagt verhielt es sich wie drei verschiedene Tools, die zusammengeklebt wurden.
Ich habe die kostenlose Stufe benutzt, mit der man nur den „Simple“-Modus verwenden kann. Bezahlte Nutzer bekommen die Bypass‑Stufen „Standard“ und „Enhanced“, daher sind meine Ergebnisse wahrscheinlich eher die Untergrenze als die Obergrenze.
Was die Detektoren gesagt haben
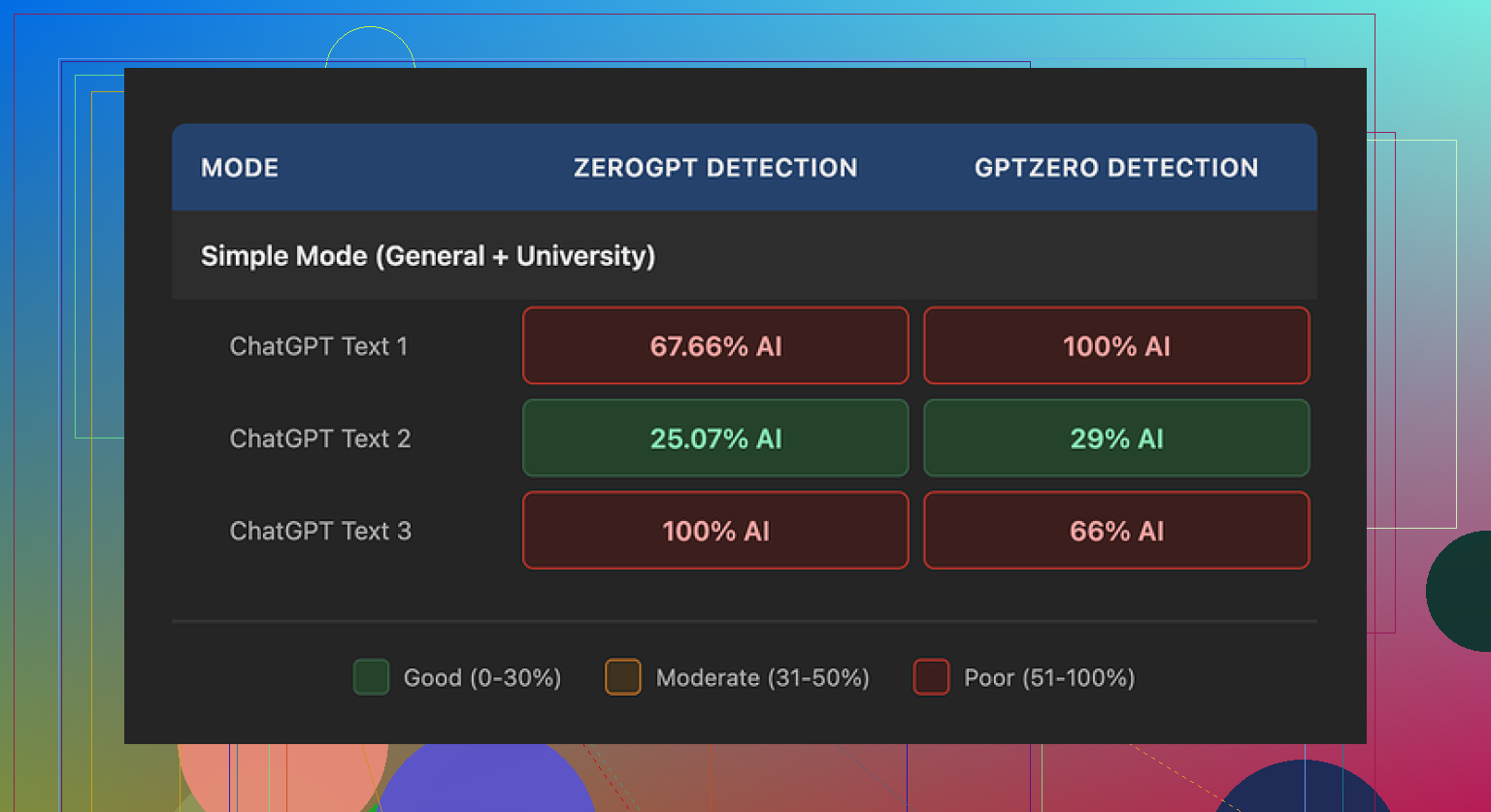
Ich habe drei verschiedene Proben durch Walter Writes AI geschickt und sie anschließend mit GPTZero und ZeroGPT geprüft.
Bester Durchlauf:
- GPTZero: 29 %
- ZeroGPT: 25 %
Für einen kostenlosen Humanizer waren diese Werte ordentlich. Die meisten anderen kostenlosen Tools, die ich ausprobiert habe, lagen deutlich höher und lösten sofort „likely AI“ aus.
Dann wurde es schräg.
Die anderen beiden Durchläufe:
- Bei beiden hat mindestens ein Detektor den Text mit 100 % AI markiert
- Einer sah nach dem „Humanizing“ schlechter aus als der ursprüngliche rohe KI‑Text
Die Leistung war also instabil. Ein Durchgang wirkte brauchbar, der nächste schrie bei jedem Detektor nach AI.
Hier ist der Screenshot von einem der Tests:
Schreibqualität und seltsame Muster
Unabhängig von den Detektoren hatte der Text selbst ein paar Auffälligkeiten, die einen Lektor misstrauisch machen würden.
Dinge, die ich immer wieder gesehen habe:
-
Semikolon‑Spam
Das Tool setzte Semikolons an Stellen, an denen ein normaler Schreiber eher ein Komma setzen oder den Satz teilen würde. Es las sich wie jemand, der Zeichensetzung aus einer Regel‑Liste gelernt und beschlossen hat, sie zu übertreiben. -
Wortwiederholungen
In einer Probe kam das Wort „heute“ viermal in drei Sätzen vor. Gleiche Position, gleicher Ton. Es fühlte sich mechanisch an. Menschen wiederholen Wörter, aber nicht in diesem Muster. -
Klammer‑Ballast
Es gab viele Klammern mit Beispielen wie „(z. B. Stürme, Dürren)“, die über den Text verteilt waren. Und dann tauchten dieselben Arten von Klammerbeispielen immer wieder auf. Dieses Muster sieht man häufig in unredigierten KI‑Texten.
Nichts davon machte den Text unlesbar, aber wenn man das jemandem gibt, der den ganzen Tag KI‑Content liest, wird er die Stirn runzeln.
Preise und Limits
Das habe ich mir zu den Preisen notiert:
- Starter: 8 Dollar pro Monat (jährliche Abrechnung), 30.000 Wörter
- Unlimited: 26 Dollar pro Monat, aber jede Einreichung ist auf 2.000 Wörter begrenzt
- Kostenlose Stufe: 300 Wörter insgesamt, nicht pro Monat
Selbst im „Unlimited“-Tarif muss man längere Texte also in Teile zerlegen. Für Leute, die an Berichten, Büchern oder langen Artikeln arbeiten, wird das schnell nervig.
Richtlinien, die mich gestört haben
Beim Lesen der Bedingungen und Formulierungen sind mir zwei Dinge aufgefallen.
-
Formulierungen zu Rückerstattung und Chargebacks
Im Abschnitt zu Rückerstattungen wurde stark auf Chargeback‑Drohungen gesetzt. Es ging um rechtliche Schritte bei Streitfällen, in einem Ton, der für ein kleines SaaS‑Tool ziemlich aggressiv wirkte. Ich prüfe beruflich viele Tools, und das kam mir unverhältnismäßig vor. -
Datenspeicherung
Ich habe keine klare, leicht verständliche Aussage dazu gefunden, wie lange eingereichte Texte gespeichert oder langfristig genutzt werden. Wenn man mit Kundentexten, Verträgen, Recherche‑Notizen oder anderen sensiblen Inhalten arbeitet, ist das wichtig.
Wenn es um Schulaufgaben oder öffentliche Blog‑Beiträge geht, ist einem das vielleicht egal. Wenn man Kundenprojekte oder vertrauliche Dokumente verarbeitet, eher nicht.
Was für mich besser funktioniert hat
Nach Tests mit mehreren Tools bin ich immer wieder bei Clever AI Humanizer gelandet. Die Ergebnisse waren dort stabiler und die Texte klangen näher an meinem Schreibstil an einem müden Tag.
Keine Anmeldegebühr, keine Kreditkarte. Du kannst es hier ausprobieren:
Dazu gibt es ein paar Community‑ und Erklärinhalte:
Humanize‑AI‑Tutorial auf Reddit
https://www.reddit.com/r/DataRecoveryHelp/comments/1l7aj60/humanize_ai/?tl=de
Clever‑AI‑Humanizer‑Review‑Thread auf Reddit
https://www.reddit.com/r/DataRecoveryHelp/comments/1ptugsf/clever_ai_humanizer_review/?tl=de
YouTube‑Video‑Review
Wenn du dich auf Basis meiner Tests zwischen Walter Writes AI und Clever AI Humanizer entscheiden willst, würde ich mit Clever anfangen, deinen üblichen Content durch beide jagen und dann vergleichen:
- Detektor‑Scores
- Wie der Text klingt, wenn du ihn laut vorliest
- Wie viel Nacharbeit du danach noch hast
Für meinen Einsatz wirkte Walter Writes AI zu inkonsistent, und die Policy‑Anmutung hat dafür gesorgt, dass ich es auf Abstand gehalten habe.
Du bildest dir das nicht ein. Walter Writes AI Reviews wirken aus einem bestimmten Grund mal treffend, mal daneben.
Offenbar mischt es gescrapete Infos, sichtbare Feature‑Checks und ein paar Vorlagen‑Meinungen. Das funktioniert bei einfachen Tools mit klaren Funktionen ganz gut. Es bricht zusammen, sobald es um Nuancen geht wie:
• Wie stabil ein Tool über längere Zeit ist
• Wie es sich in Edge Cases verhält
• Datenschutz und Umgang mit Daten
• Preisfallen und Nutzungslimits
Dadurch bekommst du einige Reviews, die detailliert und spezifisch wirken, und andere, die generisch oder sogar falsch rüberkommen. Das System testet Tools nicht so, wie es ein menschlicher Power User tun würde. Es beschreibt sie nur.
Ich widerspreche @mikeappsreviewer in einem Punkt teilweise. Detector‑Scores und AI‑Humanizing sind hilfreich, wenn du viel Content schreibst. Um Tools allgemein auszuwählen, brauchst du aber auch Dinge, in denen Walter schwach ist, wie langfristige Zuverlässigkeit, Support‑Qualität und wirkliche Nutzer‑Reibung.
Wenn du Walter weiter nutzen willst, würde ich es nur als ersten Durchgang betrachten:
- Nutze Walter, um Features, Pläne sowie grundlegende Vor‑ und Nachteile zu sammeln.
- Gleiche diese Infos mit der offiziellen Website des Tools und einem unabhängigen Review ab.
- Suche nach „[Toolname] Reddit“ oder „[Toolname] issues“ und lies mindestens 5 menschliche Kommentare.
- Ignoriere jede Walter‑Meinung, die nicht mit einem konkreten Beispiel oder einer Zahl untermauert ist.
Für AI‑Content‑Tools und „Humanizer“ würde ich mich überhaupt nicht auf Walter verlassen. Dafür brauchst du:
• Detector‑Scores von mehreren Detektoren
• Wie natürlich der Text klingt, wenn du ihn laut vorliest
• Wie viel manuelle Nachbearbeitung du danach noch machen musst
Genau da lohnt sich ein Blick auf Clever AI Humanizer. Nicht weil es Magie ist, sondern weil du schnell deine eigenen Samples durchjagen und dein Vorher‑Nachher‑Ergebnis mit dem vergleichen kannst, was Walter oder andere Review‑Bots sagen. Wenn Walter ein Tool als großartig bewertet, dein eigener Test mit Clever AI Humanizer plus einem Detector aber nur Müll ausspuckt, vertraue deinem Test.
Ein praxisnahes Setup, das du nutzen kannst:
• Schritt 1: Nutze Walter für eine erste Shortlist an Tools.
• Schritt 2: Lass für jedes Tool auf der Shortlist einen echten Workflow von dir komplett durchlaufen.
• Schritt 3: Für Schreib‑Tools: Jage den Output durch Clever AI Humanizer und zwei Detectoren und prüfe anschließend selbst die Lesbarkeit.
• Schritt 4: Führe Notizen in einer einfachen Tabelle, nicht nur im Kopf.
Wenn Walters Review und deine Notizen auseinanderlaufen, verlasse dich auf deine Daten. Walter ist als lautes, verrauschtes Signal nützlich, nicht als letzte Entscheidungsinstanz.

Du bildest dir das nicht ein, Walters Rezensionen sind tatsächlich etwas durcheinander.
Was @mikeappsreviewer und @viajantedoceu aus unterschiedlichen Blickwinkeln angedeutet haben, ist, dass Walter im Grunde ein Feature-Papagei mit Meinungen ist. Es ist ziemlich gut darin:
- Features und Preise von einer Produktseite aufzuzählen
- Vor- und Nachteile auszuspucken, die auf den ersten Blick plausibel wirken
- Selbstbewusst zu klingen, selbst wenn es nur halb richtig liegt
Wo es auseinanderfällt, ist genau das, was dir jetzt auffällt:
-
Nuancen und Sonderfälle
Walter hat Probleme mit der „unordentlichen Realität“, zum Beispiel:- Wie oft ein Tool abstürzt, hängt oder dich rate-limited
- Ob der Support wirklich antwortet, bevor das Universum erkaltet
- Versteckte Preislimits, „unbegrenzte*“ Pläne, seltsame Rückerstattungsregeln
Genau deshalb fühlen sich die Rezensionen manchmal super detailliert an, werden dann plötzlich generisch oder sind bei sehr praktischen Punkten schlicht falsch.
-
Unterschiedliche Tiefe
Manche Walter-Reviews ziehen erkennbar aus echter Dokumentation oder mehreren Quellen, daher wirken sie reichhaltig und konkret.
Andere lesen sich, als hätte jemand die Startseite 9 Sekunden überflogen und den Rest improvisiert. Dort bekommst du Widersprüche, fehlende zentrale Einschränkungen oder Lob für Features, die es gar nicht gibt oder nur in teuren Tarifen. -
Wenn KI KI-Tools bewertet, ist das… wackelig
Ich sehe den Fokus auf bloßen Detector-Scores etwas kritischer. Detectoren sind ungenau und leicht zu manipulieren.
Aber bei KI-Content-Tools ist Walter besonders schwach, weil es:- Deinen Text nicht wirklich durch Tools wie Clever AI Humanizer oder mehrere Detectoren laufen lässt
- Meist nur Fähigkeiten „beschreibt“, statt sie wirklich zu benchmarken
Wenn du also Humanizer, Paraphrasier- oder „undetectable AI“-Tools auswählst, sind Walters Reviews eher Marketing-Text als ernsthafte Tests.
-
Feine Tendenz zu „glänzend“
Ein Muster, das mir auffällt: Tools mit schicker Website, großen Versprechen und Buzzword-Buffet bekommen bei Walter oft rosigere Bewertungen, selbst wenn Nutzerfeedback anderswo gemischt ist.
Schlichte, langweilig wirkende, aber verlässliche Tools werden eher unterbewertet.
Wo Walter immer noch nützlich ist:
- Schneller Überblick, was ein Tool angeblich kann
- Grober Feature-Vergleich
- Basis-Preisübersicht (Details dann selbst nachprüfen)
Wo ich Walter fast komplett ignorieren würde:
- Alles mit sensiblen Daten, komplizierten AGB oder rechtlichen/Chargeback-Risiken
- KI-Humanizer, Plagiatstools, Detectoren, Security-Tools
- Entscheidungen, bei denen Ausfälle oder Bugs dich wirklich schädigen
Zum Thema AI-Humanizer: Wenn du viel KI nutzt, ist ein Tool wie Clever AI Humanizer viel besser testbar als jede Walter-Review. Du kannst:
- Deinen eigenen Text einfügen
- Ihn durch Clever laufen lassen
- Ihn mit ein paar Detectoren prüfen
- Laut vorlesen und schauen, wie viel du noch nachbearbeiten musst
Das sagt dir in 10 Minuten mehr als Walters „Top 10 Humanizer 2026“-Artikel jemals könnte.
Also, tl;dr zu deiner ursprünglichen Frage:
- Walter ist nicht kompletter Müll, aber definitiv nicht maßgebend.
- Nutze es als lauten, fehleranfälligen Recherche-Assistenten für den ersten Eindruck, nicht als letzte Instanz.
- Für alles Wichtige, besonders beim Thema KI-Schreiben / Humanizing, verlasse dich auf eigene Mini-Tests mit Tools wie Clever AI Humanizer plus echte Nutzerkommentare auf Reddit, in Foren usw.
- Wenn Walters Review und deine eigene praktische Erfahrung kollidieren, gilt immer: Deine Erfahrung gewinnt.
Und ja, dass du Widersprüche bemerkst, zeigt, dass dein Bullshit-Detektor funktioniert – nicht, dass du zu viel hineininterpretierst.